
‘Nul n’a droit sur l’air que je respire, ni sur la plus noble fonction de mon esprit, sur celle de juger par moi-même. Seroit-ce aux autres que j’abandonnerois le soin de penser pour moi?’,1 writes the anonymous author of Le Pot au noir, an obscure anticlerical pamphlet written on the eve of the French Revolution. It is somewhat ironic that this passage defends the right to self-expression and independence of thought while also being a word-for-word reuse of Helvetius’ De l’homme, published over fifteen years before. Yet, can one truly expect – to take a page from Foucault – to claim such independence of thought in a short anonymous polemical pamphlet? After all, to paraphrase Montaigne, are we not all continuously regurgitating those who precede us?2 One could easily argue that in an age of religious intolerance, invoking a figure such as Helvetius to advocate for the imperative of independent thought was certainly not far-fetched.3 But it turns out that this reuse of Helvetius is not an isolated event within Le Pot au noir. Thanks to a computational intertextual analysis of this text, we know that Le Pot au noir, far from being original, is to a large extent a carefully crafted combination of various borrowings, mostly from Voltaire’s Questions sur l’Encyclopédie and Helvétius’ De l’homme.4 While this case is perhaps an extreme representation of the practice of reuse in this period, it is nonetheless an illustration of the fact that texts do not exist in isolation, and that having access to the wider textual environment in which they operate can radically shift our understanding of any given text. And of course, none of this would be easily feasible without the emergence of modern digital tools, which are revolutionising the study of the period.
Indeed, over the last quarter-century, the combination of large-scale text digitisation and innovative computational techniques has had a profound impact on literary, historical and cultural studies. With wider access to texts either forgotten or difficult to access, researchers are now able to leverage innovative computational techniques, such as text mining, natural language processing, and machine learning algorithms to uncover new patterns, trends and connections within vast amounts of textual data. These techniques, typically referred to as ‘distant reading’ (see Underwood 2017), have allowed scholars to analyse complex relationships and themes over the longue-durée, and to trace the evolution of ideas and cultural practices over time. However, this new capacity to examine the ways in which cultures interact and exchange ideas, both old and new, has come at a cost: vast amounts of data generate vast amounts of results, which can make it difficult to identify relevant information, draw meaningful conclusions, and maintain a clear focus on the research question at hand. And the larger the amount of textual data, the more computational methods tend to become disconnected from the more traditional modes of research and analysis focused on the particular, thus leaving it to the researchers to bridge what can be an intractable gap between these polar opposites. Indeed, the quality and reliability of results obtained through computational methods depend on various factors, such as the quality of the digitised texts, the algorithms used, and the assumptions made during analysis. Addressing these challenges by combining digital approaches with close reading and interpretive scholarship has been central to the ARTFL Project’s efforts over the last fifteen years.5
Embracing the notion that ‘information overload’ is not an issue requiring a solution, and that an abundance of textual data offers increased opportunities for enriching the close reading experience, the ARTFL Project has built a number of tools that attempt to combine algorithmic prowess and contextualisation. However, in so doing, we realised that to understand the constant flow and evolution of ideas and concepts within a cultural system, we needed to integrate the various discrete solutions we had developed into a unified user experience, thus providing multiple perspectives – or views – on the textual data that would boost the interpretative potential of our digital approaches. Thanks to funding from the National Endowment for the Humanities, we built the Intertextual Hub, a digital platform designed to provide the best of distant and close reading experiences within a single cohesive user interface.
Guiding principles
The Intertextual Hub (https://intertextual-hub.uchicago.edu/) is an experimental digital humanities textual environment that seeks to situate specific documents – such as literary works, newspapers, parliamentary debates; in short, any textual production of a specific era – within a broader context of intertextual relations. It is our contention that texts should not be divorced from their historical and cultural environment if we wish to gain a deeper understanding of how they came to be, what drove their authors to create them, and what impact they had on their era and on future generations. More than anything, the Intertextual Hub is built around the concept of guided reading, which can be understood as a form of recommendation system, where users are suggested new works based on the content of the texts they are reading, or on the topics they are exploring. This guidance can be both active, where the user initiates a search hoping to see a wide array of texts to explore, or passive, in which case any text a user reads is linked to its wider textual environment through direct or indirect borrowings, shared topics or themes, or other kinds of lexical similarity. Thus, the Intertextual Hub offers a range of scalable reading tools which allow users to navigate between individual and larger groups of texts from both a distant and close reading perspective, one always feeding into the other in a virtuous circle.
The primary purpose of the Hub is to facilitate the contextual understanding of individual texts by integrating an extensive range of textual resources. With its roots in the rich literary heritage of 18th-century France, the Hub was initially conceptualised as a wide-ranging repository containing several large text collections from this period. These collections encompassed a diverse array of materials, including every law and decree issued during the French Revolution, alongside an impressive assortment of Revolutionary pamphlets. In addition to these primary sources, the Hub aims to feature prominent works by key figures of the Enlightenment, not only from France but also numerous translated works of renowned English authors. By compiling these varied resources, the Hub seeks to provide – as much as possible given ARTFL’s current holdings – a holistic understanding of the era, enabling users to explore the complex interplay of ideas and events that shaped the 18th-century intellectual landscape.
Of course, when designing this platform, it was crucial to address the challenges prevalent in 18th-century digital studies, such as quality discrepancies between text digitised through OCR and expertly curated materials, as well as accessibility issues related to paywalled and public resources. To overcome these obstacles, the Hub uses an innovative strategy that federates these different collections, and connects them through a web of intertextual links generated through computational methods that are less affected by problems of quality, and which are themselves completely open to all.
Collections in the Hub
As part of the Intertextual Hub, we assembled an unparalleled collection of digital resources related to the French 18th-century and Revolution, with the aim of providing a multifaceted repository of materials related to the period. Among the seven collections included in the Hub, four are open-access and anchored in the Revolutionary era. The largest of these collections is the French Revolution Collection of the Newberry Library (FRC),6 which contains over 30 000 revolutionary pamphlets that shed light on the social, political and intellectual discourses of the time. Given the size of this corpus, we had to conduct significant preliminary work to remove duplicate editions, and identify as many OCR errors as possible, bringing the final number of pamphlets down to almost 26 000. Another large corpus included is the Archives Parlementaires,7 a comprehensive compilation of parliamentary debates and proceedings between 1789 and early 1794, providing an in-depth look at the legislative processes during the first half of the French Revolution. This collection is complemented by the Baudouin Collection of Revolutionary Laws,8 which contains all the laws and decrees enacted throughout the revolutionary period. And finally, as a window into the active Revolutionary press, we included the Journaux de Marat,9 which contains 932 numbers of Marat’s Revolutionary-era journals (Figure 1).
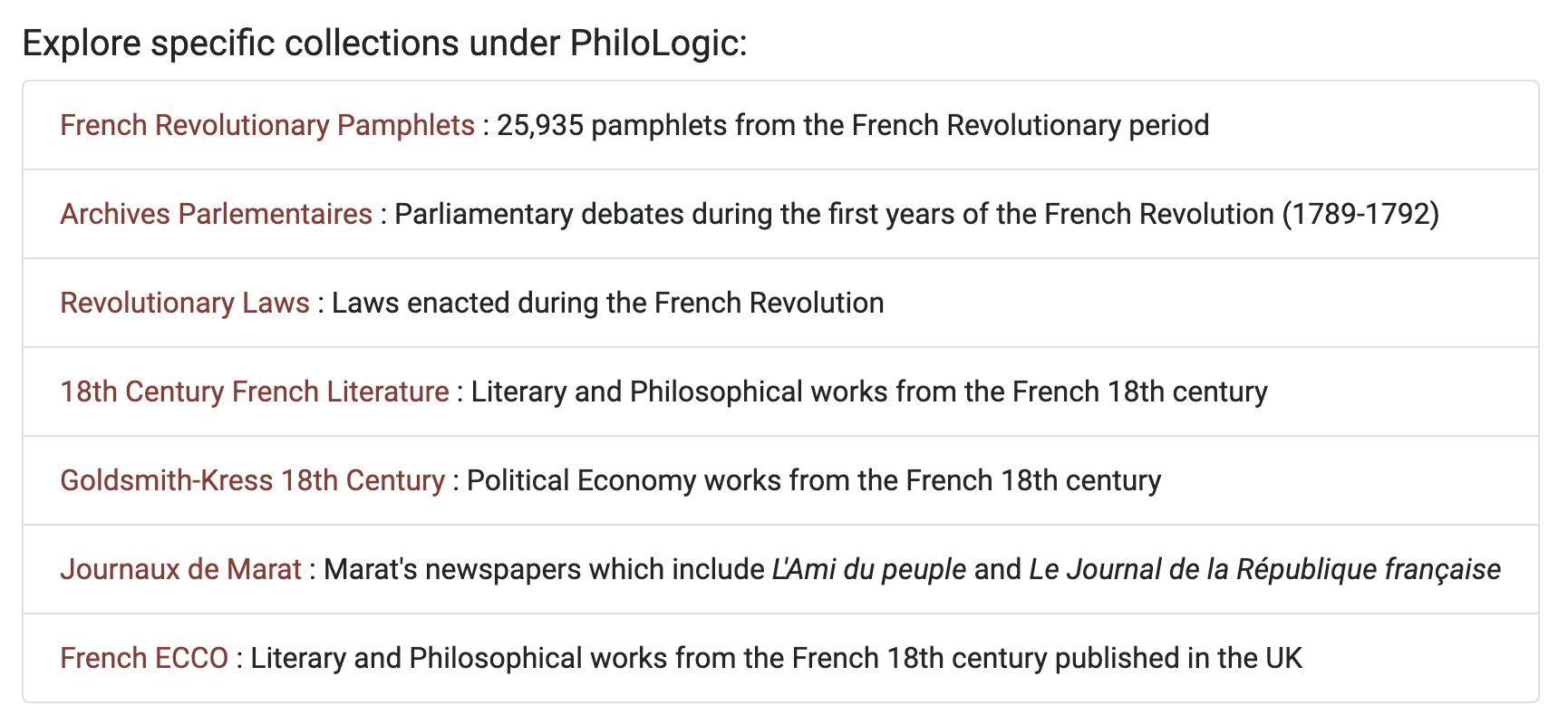
Available collections.
As one of the stated goals of this project was to build a platform that would bring together both open- and closed-access collections, we also included three access-controlled corpora, which cover much of the literary and philosophical landscape of the larger 18th century. Almost 800 works were compiled from ARTFL-Frantext,10 representing most of the works by major Enlightenment figures. This was complemented by 5000 works of political economy from the French-language subset of the Goldsmith-Kress Collection,11 which collectively capture the economic landscape and policy debates of the time. We also extracted close to 3000 French language titles from the Eighteenth Century Collections Online (ECCO),12 including many English authors in translation, thus expanding the corpus beyond the French-speaking sphere.
Apart from the access model, these collections also vary significantly in the quality of their textual data. Some texts have been keyed manually, ensuring a high level of accuracy, while others have been produced automatically from digital page images using OCR, which can occasionally result in discrepancies or errors. The lower quality inherent to texts that have been OCR-ed is certainly not the best option for traditional close reading, but we nevertheless decided to work with these texts since our distant-reading algorithms are not heavily impacted by texts with relatively low error rates. In the case of the French Revolutionary Pamphlets, we were also able to provide links to the original page images so as to enable a close-reading experience devoid of OCR errors.
Overall architecture
The Intertextual Hub’s architecture is designed with modularity and extensibility in mind, achieved through the use of a common document representation across all services powering the platform. The underlying infrastructure of the Hub is built upon the robust foundation of PhiloLogic,13 a powerful and versatile text analysis engine that has been serving ARTFL’s text collections for over two decades. The choice of this software as the backbone of our platform – beyond our familiarity with the system – comes down to the richness of its text analysis tools and its ability to handle and display various types of texts (from novels to newspapers, plays, dictionaries, and more…). Given the wide variety of collections held in the Hub, it was critical to use an indexing tool that could be customised according to the characteristics and requirements of each corpus. For example, only one of the collections, the debates of the Archives Parlementaires, has speech acts with identified speakers within the text, and we therefore made this structural element available in the PhiloLogic instance. In the context of the Intertextual Hub, the Archives Parlementaires collection becomes part of a larger set of collections combining a variety of different types of documents, with different structural elements. As a result, a user who wishes to compare the uses of a particular concept between different députés during parliamentary debates can leverage the Archives Parlementaires instance of PhiloLogic, and hence navigate the textual data within an interface customised for exploring such debates. But because we also intended these collections to be explored as a whole, we complemented these individual PhiloLogic instances with a federated search system, which effectively merges all collections into a single database, thus allowing users to query all texts contained within the Hub simultaneously. Exploring one of the results of this type of federated query – clicking on a text – takes users back to the PhiloLogic instance where this text can be read, therefore maintaining the intellectual coherence of each collection without sacrificing the interconnectedness of the Intertextual Hub.
As each text collection is integrated into a PhiloLogic instance, the data extracted from these instances are used to feed the algorithms and models that drive the Hub’s functionality. This allows for uniform preprocessing14 and data mining techniques to be employed for all textual data while retaining a connection to PhiloLogic’s data representation for traditional close reading analysis. Recognising the multifaceted nature of relationships between texts, we implemented various approaches to establish intertextual connections among the tens of thousands of texts available within the Hub. These approaches include detecting text reuses with TextPAIR,15 identifying shared themes across texts using topic modelling with TopoLogic,16 conducting nearest-neighbour searches (similar passage detection) with Annoy,17 and tracking the evolution of concepts over time employing word2vec.18 Each distant reading method stores its results within a separate database and connects to other methods through a unique identifier used by PhiloLogic for each text in the Hub. The interconnectedness of all components of the Hub is intended to facilitate the exploration of all the texts contained within as part of a larger coherent intellectual and cultural sphere.
Of course, the seamless interplay between close and distant reading within the Intertextual Hub relies heavily on having full access to the texts, which enables users to explore both the minute details of individual works and the broader patterns that emerge across collections. However, some of the collections within the Hub – Frantext, Goldsmith-Kress, and the French ECCO – have restricted access due to copyright constraints, which can partially hinder this back-and-forth dynamic. In cases where access to certain texts is limited, the Intertextual Hub still strives to provide value to researchers by offering all distant reading results associated with these collections. Although users may not have direct access to the content of these specific texts within the Hub, the distant reading results allow them to obtain bibliographic references for the restricted materials. This information can serve as a starting point for further research, guiding users to explore these texts outside of the Hub through alternative channels, such as accessing the materials through their research institutions. By providing these distant reading results even for access-controlled collections, the Intertextual Hub ensures that researchers can still glean valuable insights and maintain a certain level of engagement with all texts, perhaps paving the way for other digital projects to adopt a similar approach when working with restricted text corpora.
Distant reading perspectives
Just as the design of the infrastructure underlying the Hub was focused on facilitating the interaction between collections while maintaining the specificity of each, much effort has been put into building a user experience which brings to the fore our multifaceted approach to intertextuality, and therefore offers users multiple starting points to conduct their research, such as a single text, a concept, or a specific topic. Users can navigate the platform adopting a more traditional top-down approach via one of several entry points, such as text-reuse searching or topic modeling, or through an innovative bottom-up perspective that provides links to other related texts contained within the Hub, creating a comprehensive and interconnected research experience.
The standard starting-point is the landing page (https://intertextual-hub.uchicago.edu), which features five distinct navigational tools, each represented by a tab in the interface (Figure 2). The first entry point within the Intertextual Hub allows users to delve into individual collections by accessing their specific PhiloLogic instances. This feature enables users to search a corpus for every occurrence of a particular word, obtain word frequencies for individual texts, authors, or other metadata associated with the collection, and discover the words most frequently co-occurring with a given word. By providing these capabilities, the Intertextual Hub facilitates a targeted exploration of the texts, allowing researchers to gain deeper insights into the language patterns and relationships within specific collections. One might, for instance, seek to examine the uses of the word ‘peuple’ in Robespierre’s parliamentary speeches (Figure 3), identify legislative texts where the question of war is most prominent (Figure 4), investigate the prevalence of the term ‘patrie’ over time within the great works of the Enlightenment (Figure 5), or compare the uses of the term ‘sensation’ by Voltaire and Rousseau by examining the words that most frequently co-occur with ‘sensation’ in each of these authors’ writings (Figures 6 and 7). These are of course just a few examples of the kinds of research questions that can be explored through PhiloLogic.19 While these types of explorations can be quite enlightening, since each collection remains in its own silo – however sophisticated – they are not truly conducive to finding connections across texts and genres.
Landing page.
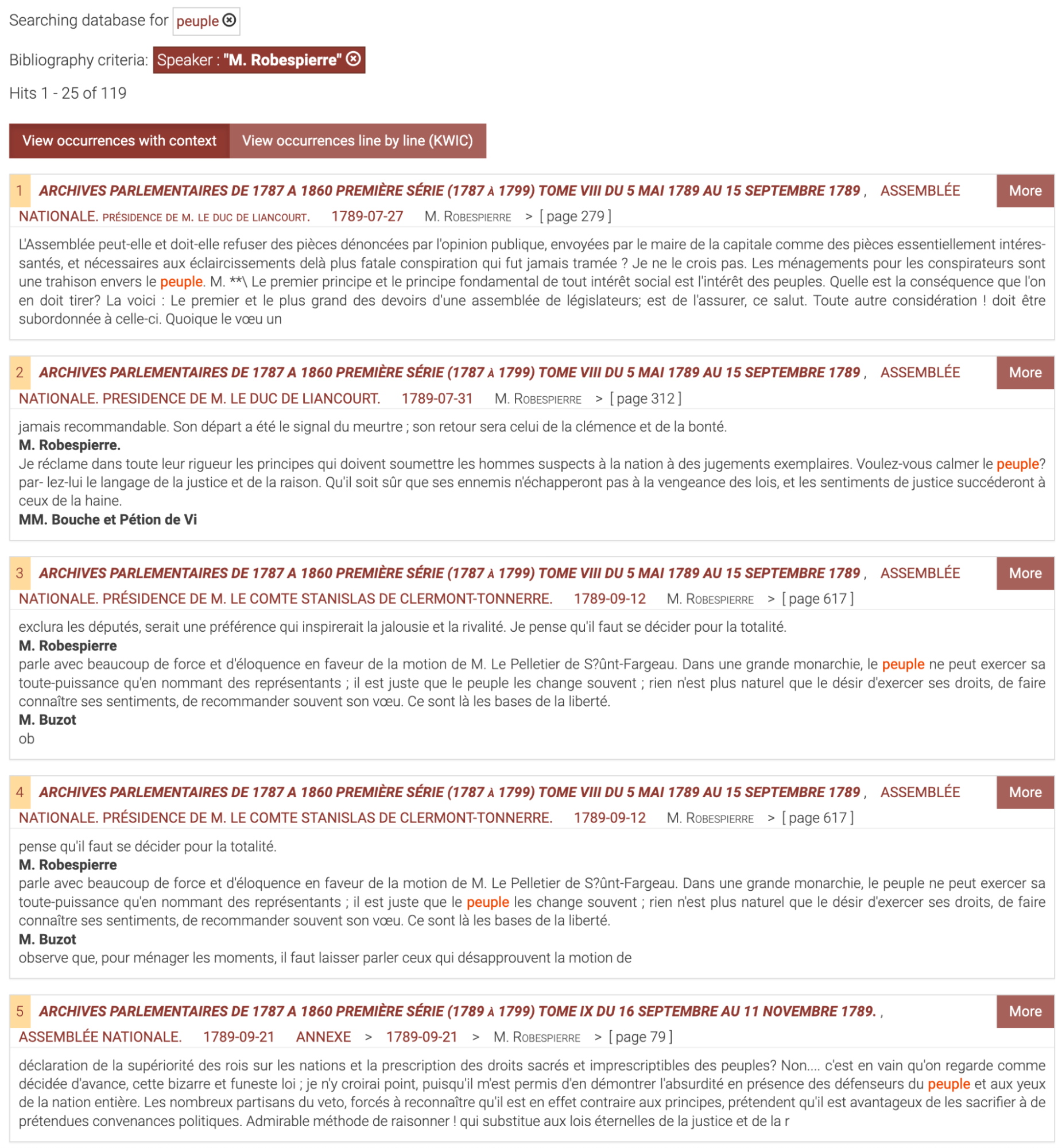
Uses of ‘peuple’ in Robespierre’s speeches to the Assemblée Nationale Constituante and the Convention in the Archives Parlementaires collection.

Relative frequency (average occurrence per 10 000 words) of the terms ‘guerre(s)’, ‘armée(s)’, ‘militaire(s)’, ‘militairement’ in individual laws and decrees from the Revolutionary Laws corpus.

Uses of the word ‘patrie’ across the entire 18th century within the 18th Century French Literature collection.

Collocations (words most frequently used in the same sentence) of the word ‘sensation’ in the works of Voltaire contained in the 18th Century French Literature collection

Collocations (words most frequently used in the same sentence) of the word ‘sensation’ in the works of Rousseau contained in the 18th Century French Literature collection.
The remaining four entry points showcase distinct distant reading techniques that emphasise the interconnectivity among the collections. Through the ‘Search and Retrieval’ tab, users can leverage the federated search system, which can simultaneously query all collections to find texts most related to a particular word, concept, or topic. For instance, one may be interested in finding in which texts the word ‘gloire’ appears frequently (Figure 8). One might also wish to leverage the ‘add most associated words’ feature, which is computed from an analysis of the contextual use of each word,20 and expand the search to include such closely related terms as ‘héros’ or ‘illustre’ (Figure 9). By manually compiling and taking note of the texts most relevant to the query term(s), researchers can then constitute a sub-corpus brought together through shared concepts or topics, which they can either explore further using the platform’s built-in features, or examine through more conventional methods thanks to the bibliographic information provided by the Hub.
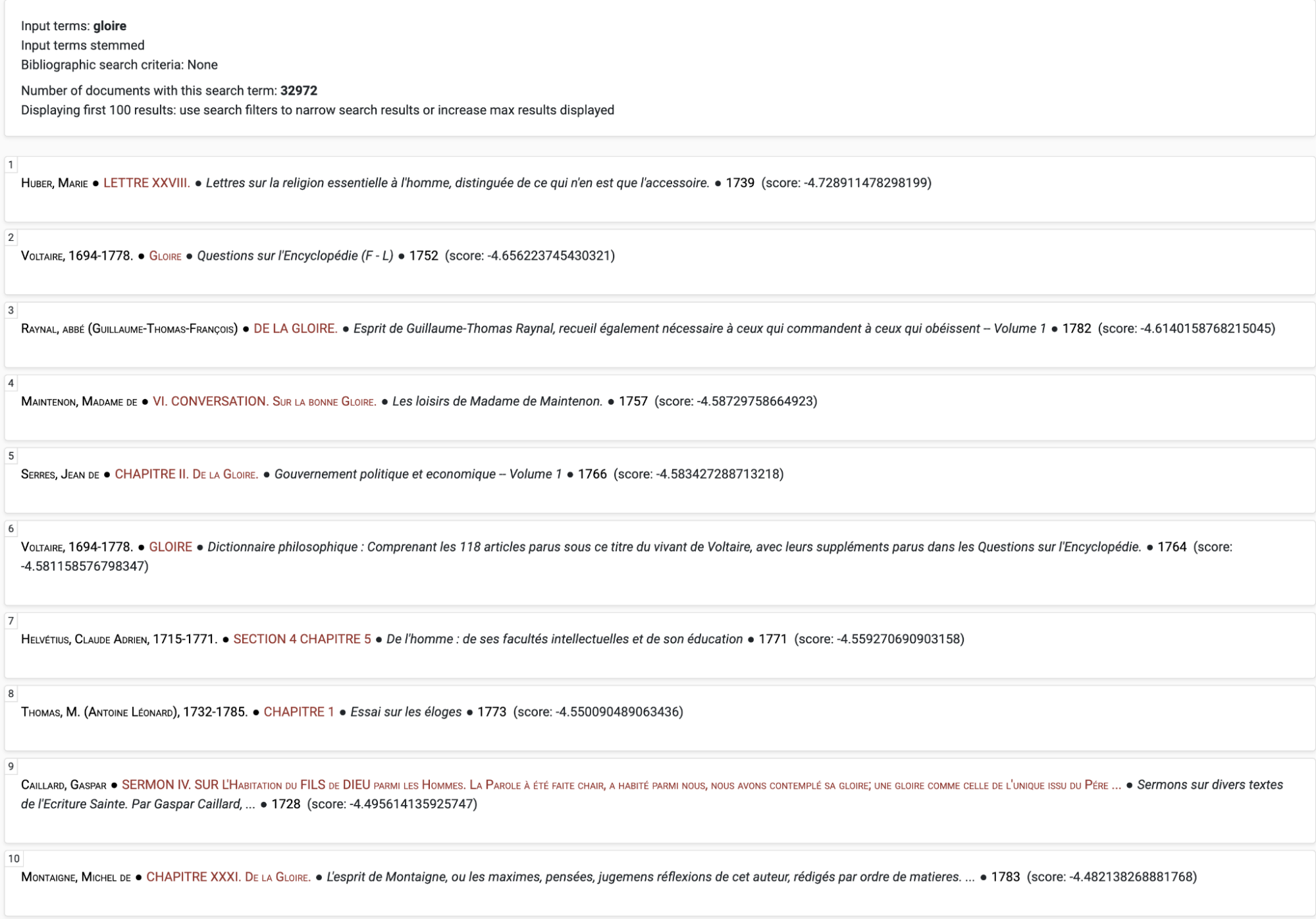
Documents in which the term ‘gloire’ features most prominently.
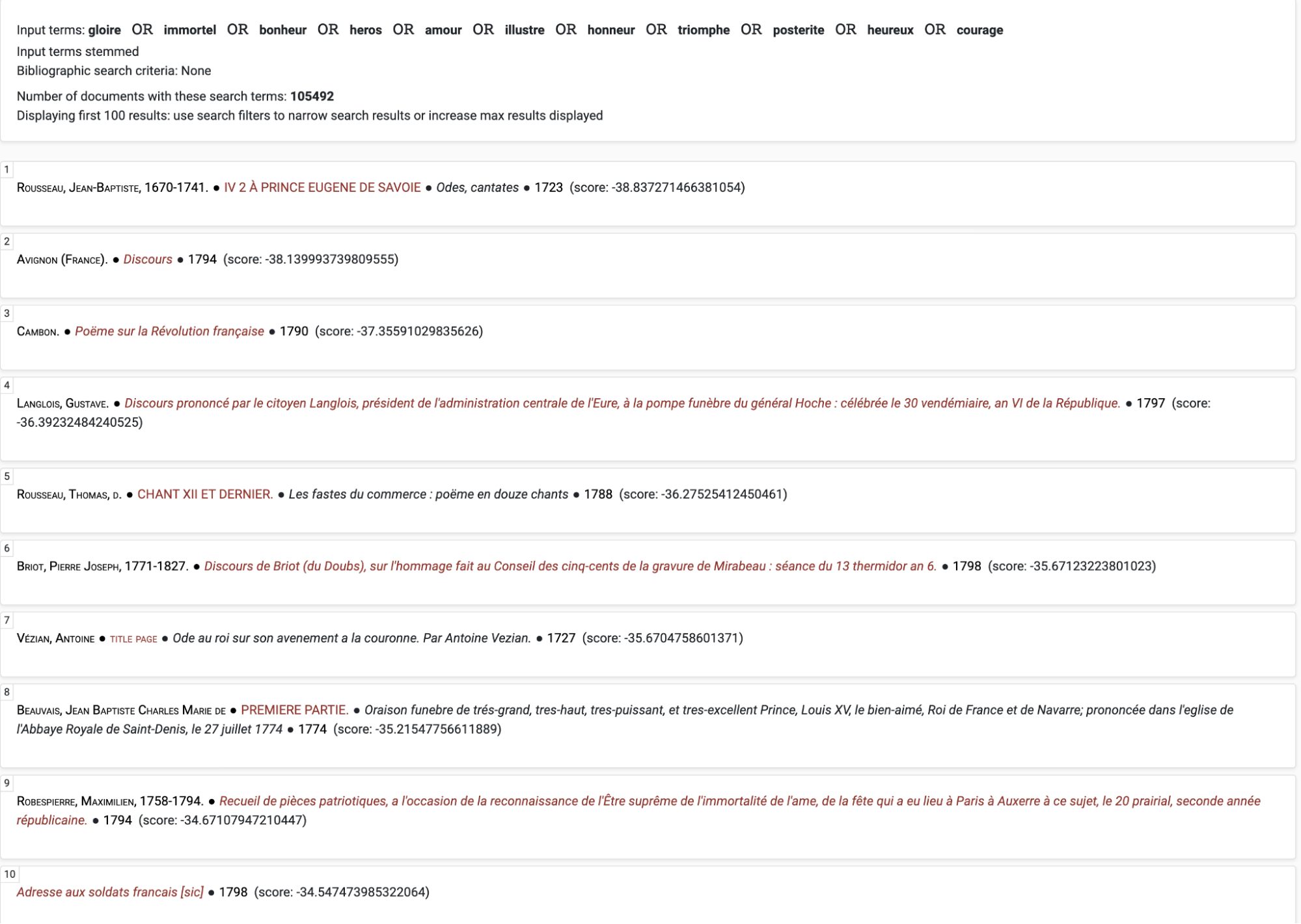
Thematic search using the ten words most frequently associated with ‘gloire’ (obtained through computational analysis of the contexts in which these words are used).
The ‘Explore text reuse’ tab lets users search for text reuses among all the different collections, such as finding which authors borrowed passages from Rousseau’s Du contrat social (Figure 10), or which texts found their way into Robespierre’s works and speeches (Figure 11). By tracing the reuse of certain phrases or passages, we can potentially form a clearer picture of the cultural and intellectual discourse of the time, understanding not only which works had an influence on others, but also gaining a glimpse into the wider network of texts that may have informed an author’s body of work. It is certainly true that reuse only draws a partial picture of influence, but this method of analysis, more perhaps than any other yet developed, highlights the interconnectedness within the tens of thousands of works found in the Intertextual Hub.
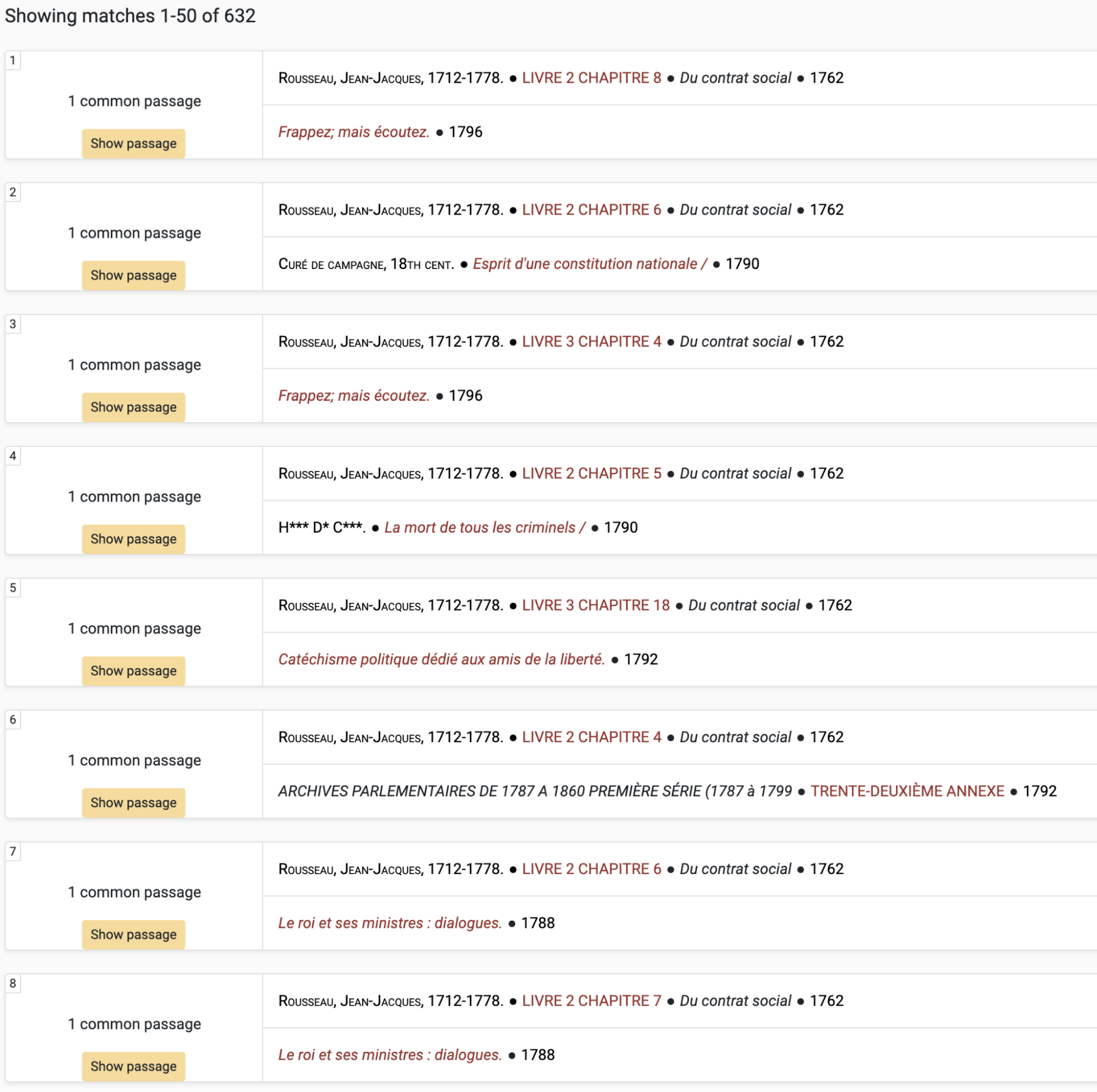
Reuses of Rousseau’s Du contrat social among all texts found in the Intertextual Hub: clicking on the ‘Show passage’ button will display the shared passage between both texts.
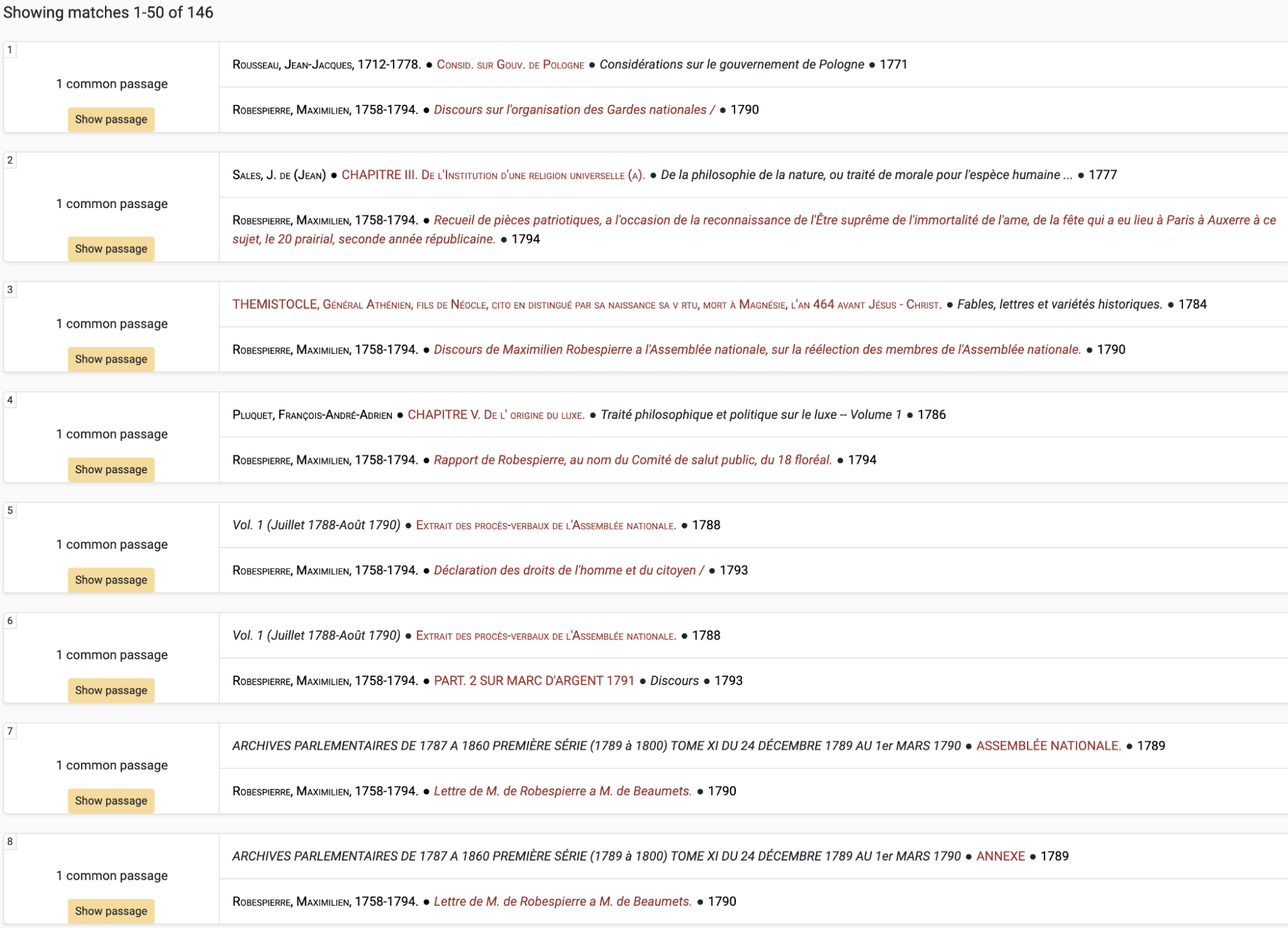
Borrowings made by Robespierre among all texts found in the Intertextual Hub.
Moving on to the ‘Explore Topics’ tab, users can visualise the variety of topics covered in our collections (Figure 12). Each topic is generated automatically from the texts housed within the Hub using a computational method called topic modelling.21 Users can then delve into an individual topic to learn more about its evolution throughout the 18th century, and identify which texts most accurately represent that particular topic (Figure 13). This mode of navigation therefore connects texts through their shared themes, again allowing users to constitute their own research corpus made up of texts that might otherwise remain disconnected or overlooked.

Sample of twenty-five topics (represented by the ten most important words in each topic) across all collections.
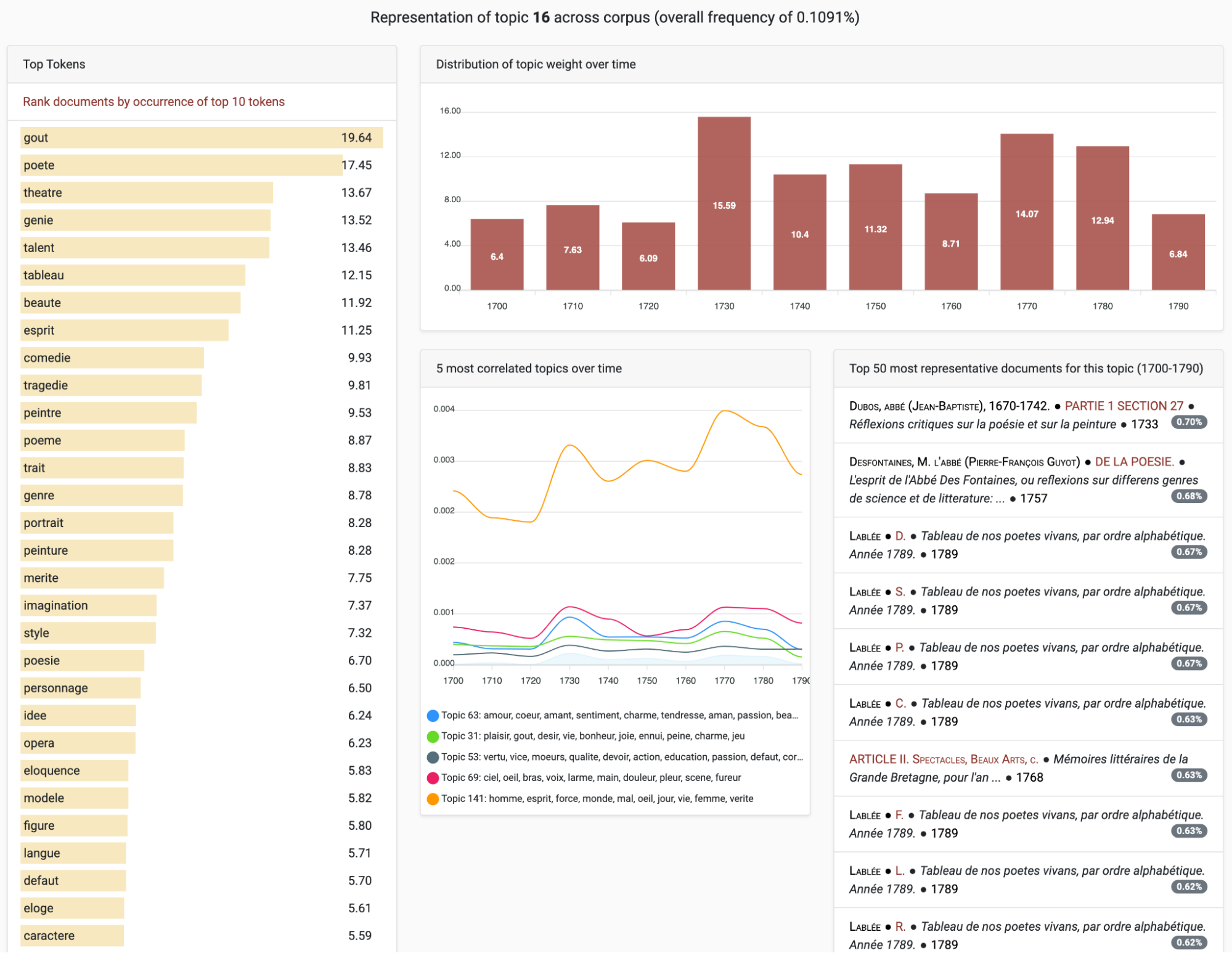
Representation of topic 16 across all collections: on the left-hand side are the most important words in that topic; the chart at top right shows the evolution of that topic’s importance in the corpus across the 18th century; the bottom middle display shows which other topics evolve in a similar fashion across the century; the list at bottom right shows the texts in which this topic features most prominently.
The last tab focuses on word usage throughout the 18th-century period from two unique and insightful perspectives. The first perspective looks into the general trends around individual word usage across the entire Intertextual Hub. This includes a listing of the topics in which words appear most frequently, as well as words that exhibit similar usage patterns (Figure 14). By contrast, the second perspective examines the evolution of individual words over time by analysing the shifting associations these words have with other words throughout the period, thereby revealing the dynamic nature of language and the evolution of concepts (Figure 15). By providing these complementary views on word usage, the Intertextual Hub offers users a more comprehensive understanding of the linguistic landscape and the unfolding of ideas across our diverse collections.

Representation of the word ‘genie’ across all collections: the top left shows the topics in which the word occurs most prominently, the right-hand side shows the documents in which the word is most important, and the bottom left section presents two different measures of strongly correlated words.

Evolution of the word ‘genie’ across the 18th century.
While these entry points are designed to help researchers narrow their focus around a set of interconnected texts, one crucial aspect that they also share is the way in which they redirect back to the original texts themselves. Clicking on a text link presents users with two choices. The first option takes them to the text itself, where they can engage with our innovative close reading experience, which will be explained in the next section. The second option offers a topical interpretation of the text, breaking down the topics found within it and identifying other texts considered similar based on their topical composition and shared vocabulary (Figure 16). By providing these different options, the Intertextual Hub again enables users to explore texts and their relationships from multiple angles, enriching their overall research experience.

Distant reading perspective on chapter 8 of Louis-Sébastien Mercier’s Du théâtre, ou, Nouvel essai sur l’art dramatique: the top sections show the most prominent topics found in this text, and the most important words present in the text. The bottom section offers two different measures of document similarity.
Close reading in an interconnected web of relationships
As mentioned above, when users opt to navigate to the text itself – referred to as ‘Reading the text’ in the user interface – they are led to what is perhaps the most distinctive feature of the Intertextual Hub: our guided reading interface. Ultimately, all of the distant reading techniques offered in the Hub eventually lead to the reading experience, where researchers are able to corroborate the suggestive patterns unearthed by the computational methods through active, engaged reading. However, what sets our platform apart from other digital humanities tools, and what truly fulfils our goal of creating an interconnected experience between close and distant reading perspectives, is the additional context we provide within the reading experience itself.
By leveraging the intertextual algorithms that fuel our distant reading approach, users who navigate to the reading interface are immediately presented with a list of other texts that bear semantic similarities to the text displayed on the page (Figure 17), as well as any potential shared passages found in other texts. These could be instances where a passage from the text at hand has been reused by later authors (Figure 18), or where it borrows passages from earlier works (Figures 19 and 20). Returning to our earlier example of Le Pot au noir, Figures 19 and 20 show how the Intertextual Hub gives a quick overview of its deeply intertextual nature. Having the reused passages highlighted within the running text allows readers to visualise how this particular text was assembled. Researchers can even investigate if the reused sections have been altered from the original text by clicking on any individual reuse (Figure 21). Of course, texts are not thematic monoliths, and researchers may be interested in identifying related texts based on a small fragment of text only, such as a few sentences, or a paragraph. Recognising this need to explore thematic connections at a more granular level, the Intertextual Hub also lets users select a specific passage within the reading interface to identify texts that closely align with the chosen excerpt (Figure 22).
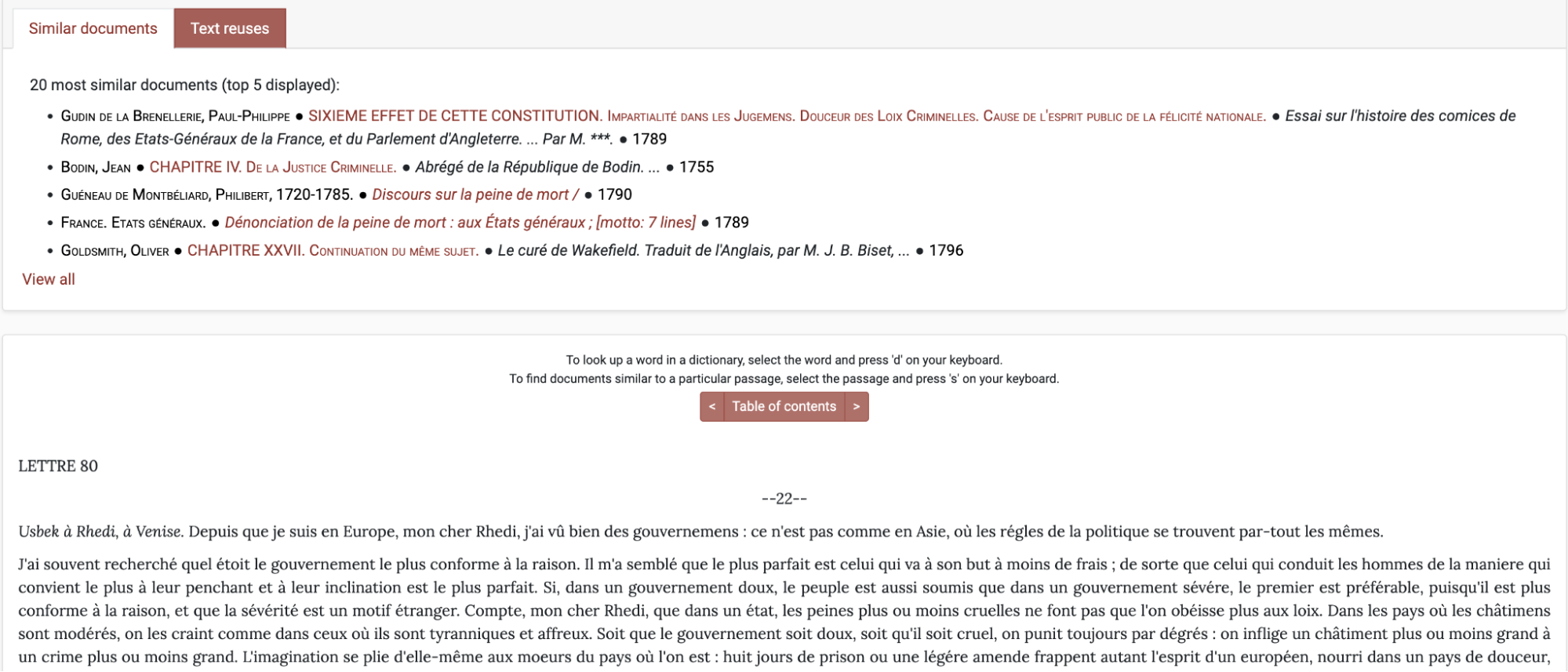
Lettre 80 from Montesquieu’s Lettres persanes: the close reading interface suggests five similar texts based on semantic similarity.

Lettre 80 from Montesquieu’s Lettres persanes: selecting the ‘Text reuses’ tab highlights reuses of this letter in later texts, and hovering over a highlighted passage (as seen in the figure) shows where the passage is reused.

Sources for all reuses found in the pamphlet Le Pot au noir (screenshot does not show the complete list of passages from De l’homme).

Part of the pamphlet Le Pot au noir with the passages that represent reuses in red: these passages are for the most part based on De l’homme, with a short extract from Voltaire’s article ‘Dieu’ in the Questions sur l’Encyclopédie.

Viewing differences between the source passage and its subsequent reuse: sections in green in the source have been removed in the reuse, and sections in darker red in the reuse are additions to the original passage.

Most similar documents to the following passage, which is highlighted in the text behind the pop-up: ‘Nous avons en nous deux facultés, ou, si je l’ose dire, deux puissances passives, dont l’existence est généralement et distinctement reconnue. L’une est la faculté de recevoir les impressions différentes que font sur nous les objets extérieurs; on la nomme sensibilité physique. L’autre est la faculté de conserver l’impression que ces objets ont faite sur nous; on l’appelle mémoire: et la mémoire n’est autre chose qu’une sensation continuée, mais affoiblie.’ (Helvétius, De l’esprit, 1758)
In short, thanks to all the intertextual links gathered from distant reading methods, the close reading user interface completely transforms the process of traditional text analysis by instantly situating any reading within the historical and intellectual context of the period. In this paradigm, close reading is no longer conducted with each text in isolation, detached from its wider context. Instead, it is carried out in a dynamic space where relationships between texts, authors and ideas are constantly made evident, and where readers are guided towards new, intriguing avenues to explore based on their thematic interests. Our reading interface is a space where the broader context of a text comes alive, bringing to the fore interconnected literary or philosophical networks and sparking deeper insights into the cultural and intellectual currents of the period.
Impact, limitations and future perspectives
The Intertextual Hub represents a significant milestone in 18th-century studies and the broader field of digital humanities. Its core ambition is to foster a deeply interconnected research experience by bridging the gap between close and distant reading techniques. In doing so, the platform aims to enhance our understanding of the vast corpus of texts from the 18th-century period, bringing to light the complex web of intellectual exchanges that shaped this critical era. Through its integration of computational methods with traditional humanities research practices, the Hub embodies the potential of digital tools to enrich scholarly inquiry, perhaps offering a model for how digital humanities can bring fresh insights and methods to the study of historical texts and periods.
Of course, like all tools, the Intertextual Hub has its limitations, which in turn provide several potential avenues for future development. For instance, while the platform excels at bringing together texts through shared passages, ideas or themes, it is unable to analyse such sub-corpora on their own, isolated from the rest of the Hub, a process which could perhaps reveal deeper connections between texts. Additionally, while the Hub currently focuses on 18th-century French texts, expanding the scope to include other periods, and perhaps to other languages,22 could greatly enhance its value as a research tool. As the field of digital humanities continues to evolve and mature, and as new strides are made within the realm of computational methods for text analysis, it will be exciting to see how platforms like the Intertextual Hub develop and adapt to better serve the ever-evolving needs of researchers.
Notes
- ‘None have the right to the air I breathe, nor to the noblest function of my mind, that of judging for myself. Would I leave to others the task of thinking for me?’. Translation is my own. [^]
- Montaigne famously wrote in his Essais: ‘nous ne faisons que nous entregloser’ (book 3, ch.13; Montaigne 2007, p.1115). [^]
- Although such autonomy of the mind as claimed in the original passage may be somewhat contradictory within Helvétius’ own thought on the development of one’s self. [^]
- While a majority of the text was identified as being sourced from these and other texts, the sections not recognised as reuses may indeed be borrowings as well, conceivably from texts not included in our computational analysis at the time. One could perhaps argue that the originality of the pamphlet stems from its careful combination of various passages. [^]
- Some notable articles describing these efforts include Horton et al. 2009, Allen et al. 2010, and Cooney, Roe and Olsen 2020. [^]
- For more information on the FRC, see https://www.newberry.org/collection/research-guide/french-pamphlets. [^]
- For more information on the Archives Parlementaires, see https://artfl-project.uchicago.edu/archives-parlementaires. [^]
- For more information on the Baudouin collection, see https://artfl-project.uchicago.edu/collection-baudouin. [^]
- For more information on the Journaux de Marat, see https://artfl-project.uchicago.edu/content/lami-du-peuple. [^]
- For more information on ARTFL-Frantext, see https://artfl-project.uchicago.edu/content/artfl-frantext. [^]
- For more information on the Goldsmith-Kress collection, see https://www.gale.com/intl/c/making-of-the-modern-world-part-i. [^]
- For more information on the ECCO collection, see https://www.gale.com/intl/primary-sources/eighteenth-century-collections-online. [^]
- PhiloLogic is a powerful full-text search, retrieval and analysis tool designed for large-scale collections of texts, particularly suited for the needs of scholars in the humanities and social sciences. For more information, see https://github.com/ARTFL-Project/PhiloLogic4. [^]
- This preprocessing involves various word normalisation techniques such as lemmatisation, or the removal of all accents to account for orthographic variants. For instance, words such as ‘intérêts’ are normalised to ‘interet’. [^]
- TextPAIR is a high-performance sequence aligner designed to identify similar passages in large text collections. See https://github.com/ARTFL-Project/text-pair for more information. [^]
- TopoLogic is a topic modelling browser designed to explore the automatic classification of textual corpora. See https://github.com/ARTFL-Project/TopoLogic for more information. [^]
- Annoy is a software package that provides a high-performance method of finding similar vectors within a large collection of vectors. We use it as an optimisation of the vector space model in order to find similar texts based on semantic similarity. For more information on Annoy, see https://github.com/spotify/annoy. [^]
- Word2vec is an algorithm that builds vector representations of words based on the context in which they are used. In this model, words used in similar contexts are deemed closely related. For more information on word2vec, see Mikolov et al., 2013. [^]
- For more examples of uses of PhiloLogic, see Cooney, Roe and Olsen 2013, or Morrissey, Roe and Gladstone 2016. [^]
- This feature is driven by the word2vec computational model. [^]
- For more information on topic modelling and its uses in Digital Humanities, see Blei 2012. For a more concrete application on the French Enlightenment, see Roe, Gladstone and Morrissey 2016. [^]
- The advent of large multilingual language models is rapidly making sophisticated cross-lingual analysis a tangible possibility. However, it is important to recognise that the currently accessible multilingual language models, often available via the Hugging Face hub (https://huggingface.co/), may not be as advanced as the as-yet-unreleased models developed by companies such as OpenAI or Google. Therefore, the availability of sophisticated open-source cross-lingual textual analytics is highly dependent on the continued availability of newer and more performant models. [^]
References
Allen T., Cooney C., Douard S., Horton R., Morrissey R., Olsen M., Roe G. and Voyer R. 2010. ‘Plundering philosophers: identifying sources of the Encyclopédie’. In Journal of the Association for History and Computing 13:1. http://hdl.handle.net/2027/spo.3310410.0013.107.
Blei D. 2012. ‘Topic modeling and Digital Humanities’. In: Journal of Digital Humanities 2:1. https://journalofdigitalhumanities.org/2-1/topic-modeling-and-digital-humanities-by-david-m-blei/.
Cooney C., Roe G. and Olsen M. 2013. ‘The notion of the “textbase”: design and use of textbases in the humanities’. In: Price K. and Siemens R. (eds) Literary Studies in the Digital Age: An Evolving Anthology. New York: Modern Language Association of America. https://dlsanthology.mla.hcommons.org/the-notion-of-the-textbase/.
Cooney C. and Gladstone C. 2020. ‘Opening new paths for scholarship: algorithms to track text reuse in ECCO’. In: Burrows S. and Roe G. (eds) Digitizing Enlightenment: Digital Humanities and the Transformation of Eighteenth-Century Studies. Oxford University Studies in the Enlightenment. Liverpool: Liverpool University Press, 353–74.
Horton R., Morrissey R., Olsen M., Roe G. and Voyer R. 2009. ‘Mining eighteenth century ontologies: machine learning and knowledge classification in the Encyclopédie’. In: Digital Humanities Quarterly 3:2. https://www.digitalhumanities.org/dhq/vol/3/2/000044/000044.html.
Mikolov M., Chen K., Corrado G. and Dean J. 2013. ‘Efficient estimation of word representations in vector space’. doi.org/10.48550/arXiv.1301.3781.
Montaigne M. de 2007. Les Essais. Balsamo J., Magnien M. and Magnien-Simonin C. (eds) Bibliothèque de la Pléiade. Paris: Gallimard.
Morrissey R., Roe G. and Gladstone C. 2006. ‘La littérature à l’âge des algorithmes’. In: Revue d’Histoire littéraire de la France 116:3, 595–617.
Roe G., Gladstone C. and Morrissey R. 2016. ‘Discourses and disciplines in the Enlightenment: topic modeling the French Encyclopédie’. In: Frontiers in Digital Humanities 2:8 (January). https://doi.org/10.3389/fdigh.2015.00008.
Underwood T. 2017. ‘A genealogy of distant reading’. In: Digital Humanities Quarterly 11:2. http://www.digitalhumanities.org/dhq/vol/11/2/000317/000317.html.